2025
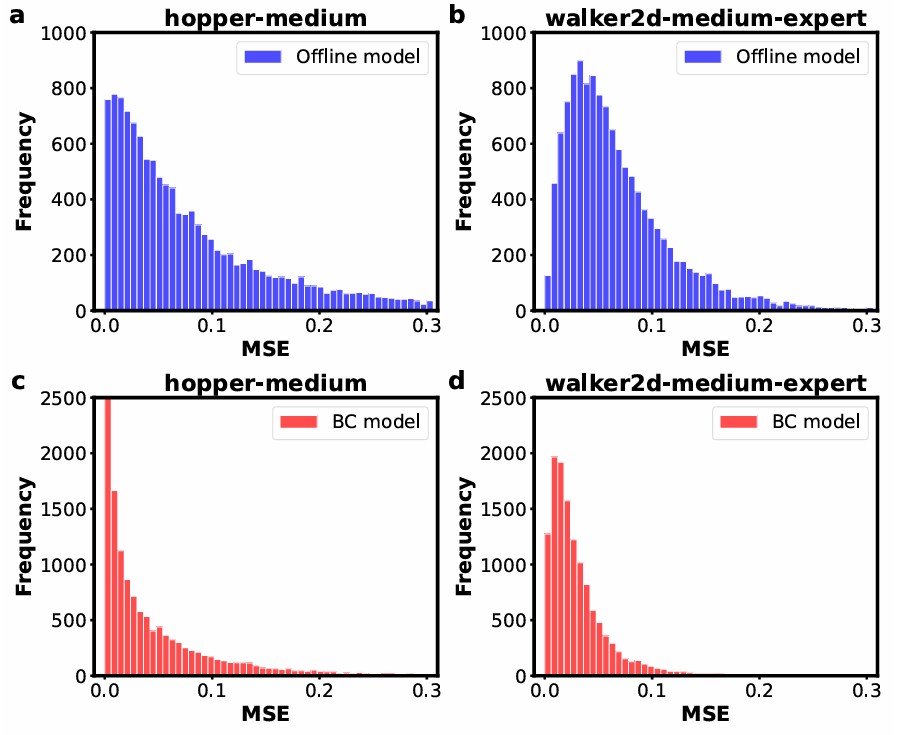
Behavior-Adaptive Q-Learning: A Unifying Framework for Offline-to-Online RL
Lipeng Zu, Hansong Zhou, Xiaonan Zhang
arXiv:2511.03695 [cs.LG]
Offline reinforcement learning (RL) enables training from fixed data without online interaction, but policies learned offline often struggle when deployed in dynamic environments due to distributional shift and unreliable value estimates on unseen state-action pairs. We introduce Behavior-Adaptive Q-Learning (BAQ), a framework designed to enable a smooth and reliable transition…
Full abstract
Behavior-Adaptive Q-Learning: A Unifying Framework for Offline-to-Online RL
Lipeng Zu, Hansong Zhou, Xiaonan Zhang
arXiv:2511.03695 [cs.LG]
Offline reinforcement learning (RL) enables training from fixed data without online interaction, but policies learned offline often struggle when deployed in dynamic environments due to distributional shift and unreliable value estimates on unseen state-action pairs. We introduce Behavior-Adaptive Q-Learning (BAQ), a framework designed to enable a smooth and reliable transition…
Full abstract
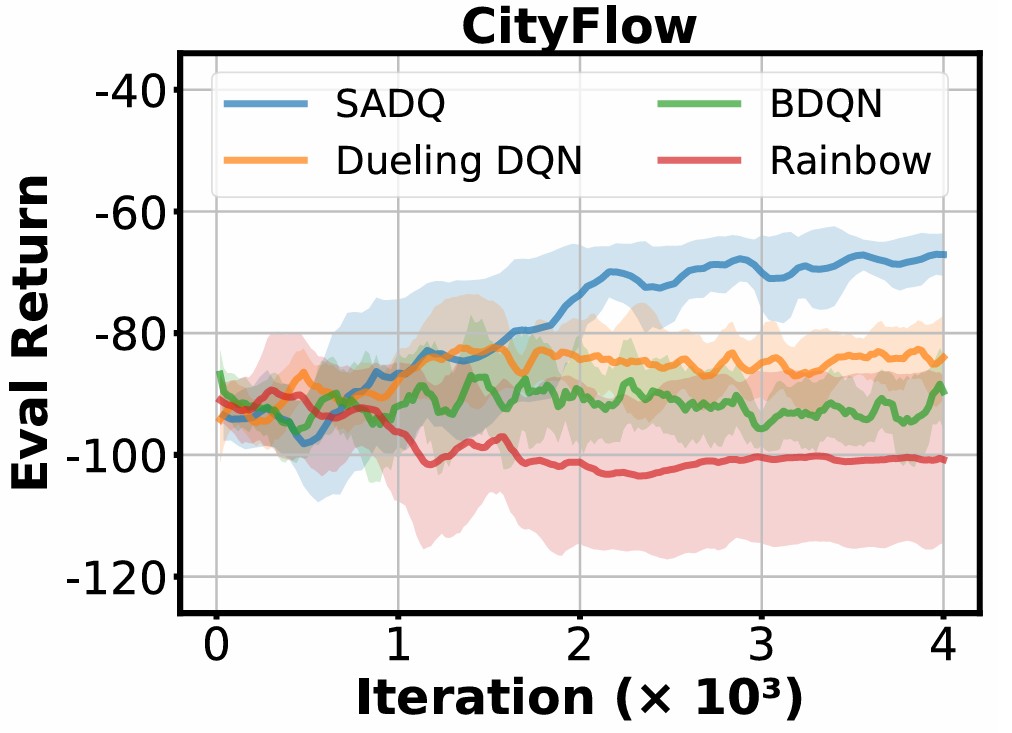
Enhancing Q-Value Updates in Deep Q-Learning via Successor-State Prediction
Lipeng Zu, Hansong Zhou, Xiaonan Zhang
arXiv:2511.03836 [cs.LG]
Deep Q-Networks (DQNs) estimate future returns by learning from transitions sampled from a replay buffer. However, the target updates in DQN often rely on next states generated by actions from past, potentially suboptimal, policy. As a result, these states may not provide informative learning signals, causing high variance into the…
Full abstract
Enhancing Q-Value Updates in Deep Q-Learning via Successor-State Prediction
Lipeng Zu, Hansong Zhou, Xiaonan Zhang
arXiv:2511.03836 [cs.LG]
Deep Q-Networks (DQNs) estimate future returns by learning from transitions sampled from a replay buffer. However, the target updates in DQN often rely on next states generated by actions from past, potentially suboptimal, policy. As a result, these states may not provide informative learning signals, causing high variance into the…
Full abstract
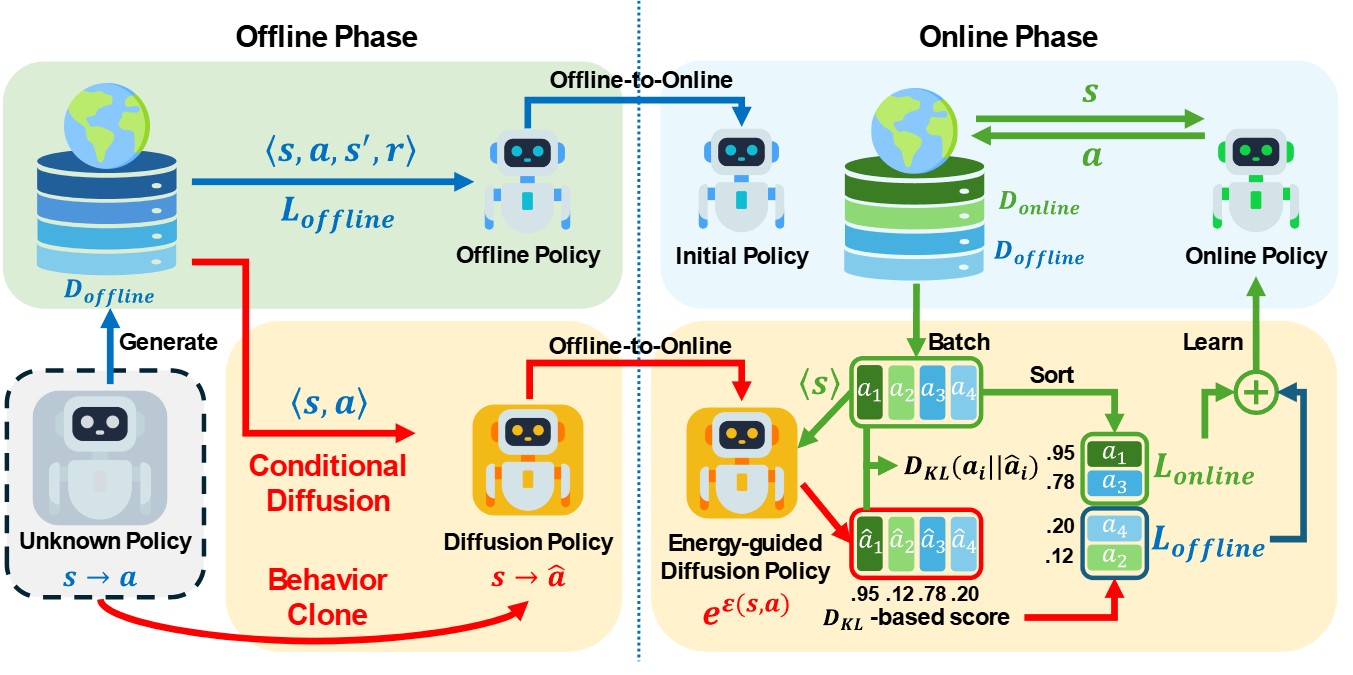
From Static Constraints to Dynamic Adaptation: Enabling Safe Constraint Release in Offline-to-Online Reinforcement Learning
Submitted to ICLR '26: International Conference on Learning Representations
Transitioning from offline to online reinforcement learning (RL) is challenging because the conservative objectives used by offline algorithms must be gradually released during fine-tuning. Naively removing these objectives often destabilizes training, while keeping them uniformly suppresses adaptation. To address this problem, we propose the Dynamic Alignment for Release, a method…
Full abstract
From Static Constraints to Dynamic Adaptation: Enabling Safe Constraint Release in Offline-to-Online Reinforcement Learning
Submitted to ICLR '26: International Conference on Learning Representations
Transitioning from offline to online reinforcement learning (RL) is challenging because the conservative objectives used by offline algorithms must be gradually released during fine-tuning. Naively removing these objectives often destabilizes training, while keeping them uniformly suppresses adaptation. To address this problem, we propose the Dynamic Alignment for Release, a method…
Full abstract
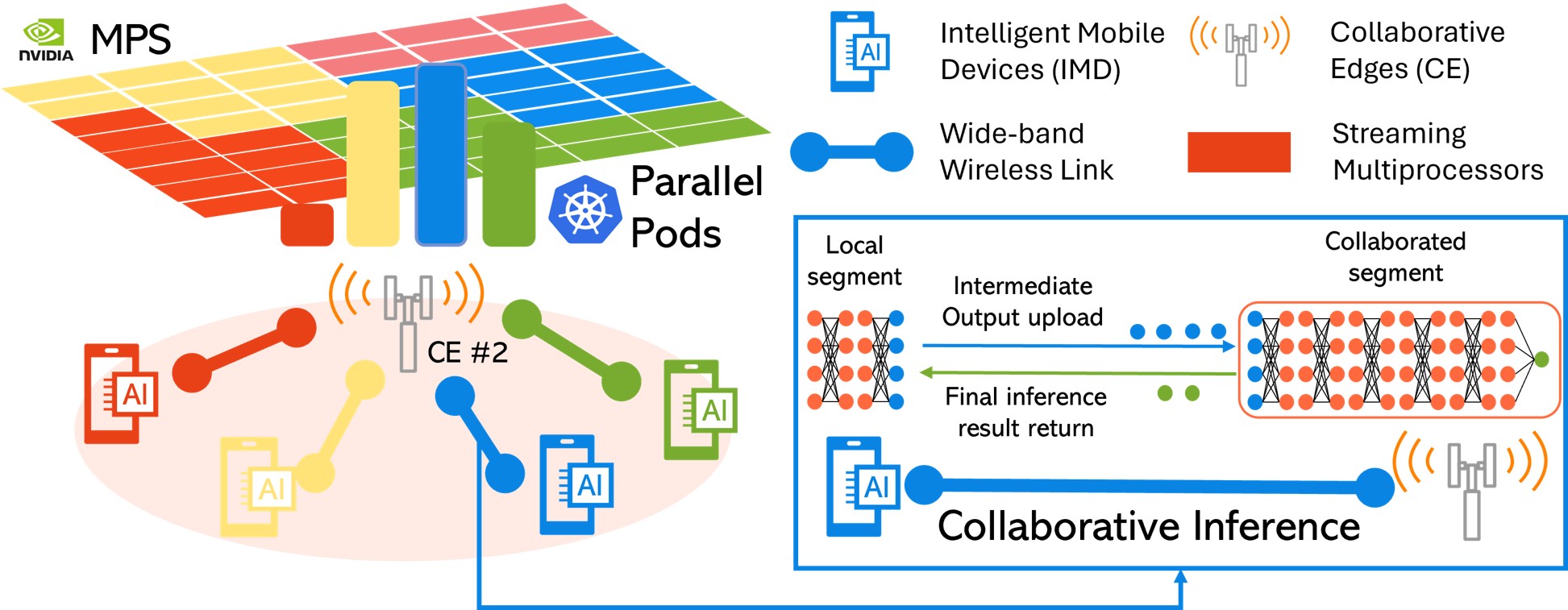
Fairness-Oracular MARL with Competitor-Aware Signals for Collaborative Inference
Hansong Zhou, Xiaonan Zhang
NeurIPS '25 - AI4NextG: The Thirty-Ninth Annual Conference on Neural Information Processing Systems
Collaborative inference (CI) in NextG networks enables battery-powered devices to collaborate with nearby edges on deep learning inference. The fairness issue in a multi-device multi-edge (M2M) CI system remains underexplored. Mean-field multi-agent reinforcement learning (MFRL) is a promising solution for its low complexity and adaptability to system dynamics. However, the…
Full abstract
Fairness-Oracular MARL with Competitor-Aware Signals for Collaborative Inference
Hansong Zhou, Xiaonan Zhang
NeurIPS '25 - AI4NextG: The Thirty-Ninth Annual Conference on Neural Information Processing Systems
Collaborative inference (CI) in NextG networks enables battery-powered devices to collaborate with nearby edges on deep learning inference. The fairness issue in a multi-device multi-edge (M2M) CI system remains underexplored. Mean-field multi-agent reinforcement learning (MFRL) is a promising solution for its low complexity and adaptability to system dynamics. However, the…
Full abstract
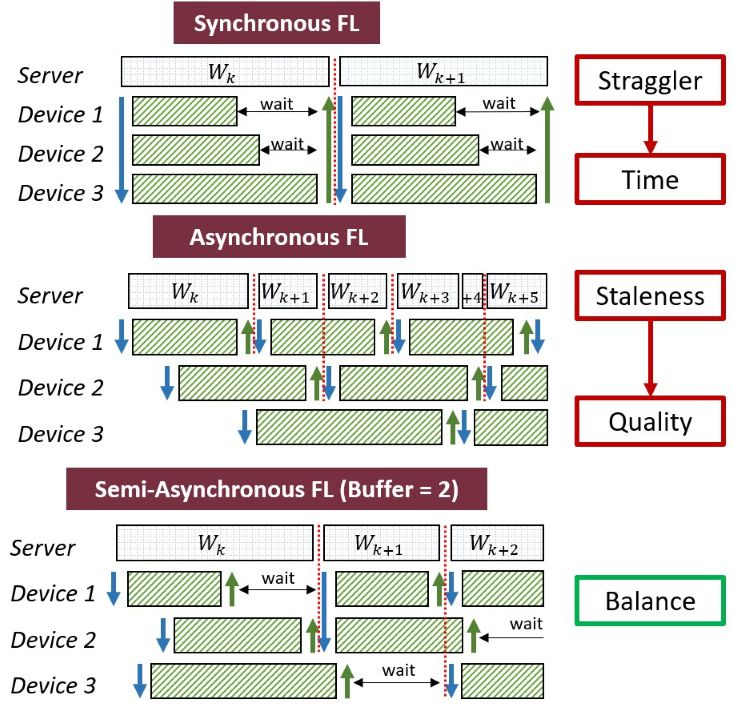
Similarity-Guided Rapid Deployment of Federated Intelligence Over Heterogeneous Edge Computing
Hansong Zhou, Jingjing Fu, Yukun Yuan, Linke Guo, Xiaonan Zhang
INFOCOM '25: IEEE Conference on Computer Communications
Edge computing is envisioned to enable rapid federated intelligence on edge devices to satisfy their dynamically changing AI service demands. Semi-Asynchronous FL (Semi-Async FL) enables distributed learning in an asynchronous manner, where the server does not have to wait all local models for improving the global model. Hence, it takes…
Full abstract
Similarity-Guided Rapid Deployment of Federated Intelligence Over Heterogeneous Edge Computing
Hansong Zhou, Jingjing Fu, Yukun Yuan, Linke Guo, Xiaonan Zhang
INFOCOM '25: IEEE Conference on Computer Communications
Edge computing is envisioned to enable rapid federated intelligence on edge devices to satisfy their dynamically changing AI service demands. Semi-Asynchronous FL (Semi-Async FL) enables distributed learning in an asynchronous manner, where the server does not have to wait all local models for improving the global model. Hence, it takes…
Full abstract
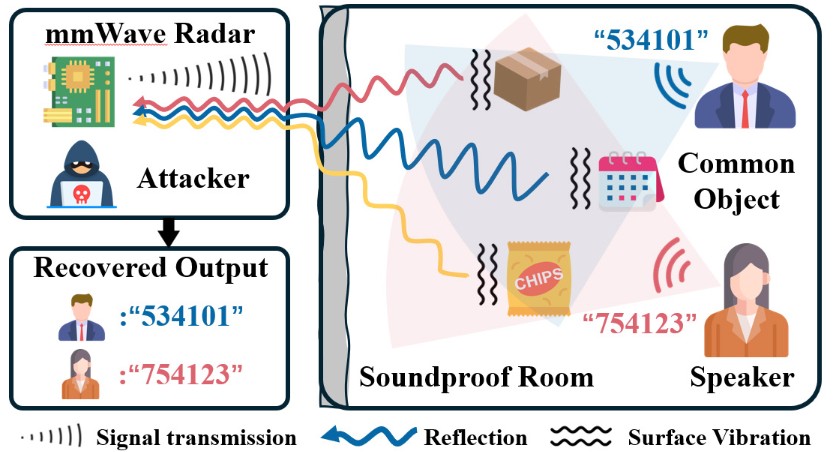
Non-Intrusive Speaker Diarization via mmWave Sensing
Shaoying Wang, Hansong Zhou, Yukun Yuan, Xiaonan Zhang
Sensys '25: Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems (Poster)
Speaker diarization refers to identifying who speaks what in a conversation. It is critical in sensitive settings like psychological counseling and legal consultations. However, traditional approaches, such as microphone or video, raise privacy concerns and cause discomfort to participants due to their noticeable deployment. To address this, we propose a…
Full abstract
Non-Intrusive Speaker Diarization via mmWave Sensing
Shaoying Wang, Hansong Zhou, Yukun Yuan, Xiaonan Zhang
Sensys '25: Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems (Poster)
Speaker diarization refers to identifying who speaks what in a conversation. It is critical in sensitive settings like psychological counseling and legal consultations. However, traditional approaches, such as microphone or video, raise privacy concerns and cause discomfort to participants due to their noticeable deployment. To address this, we propose a…
Full abstract
2024
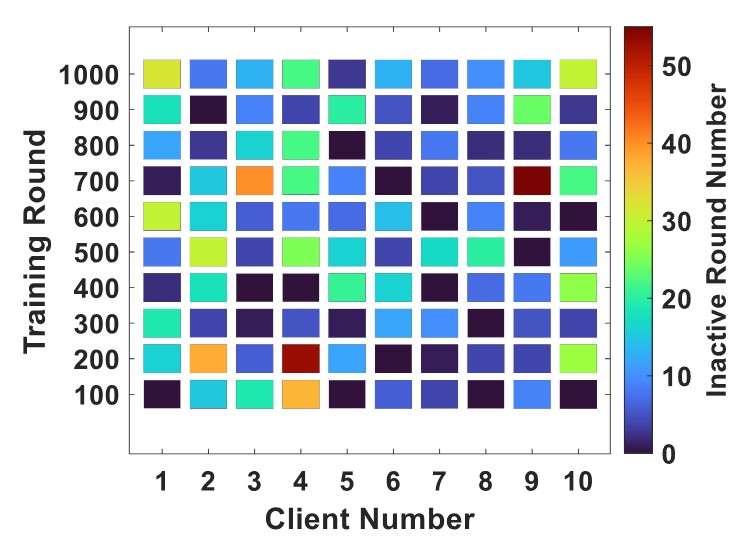
Fedar: Addressing client unavailability in federated learning with local update approximation and rectification
Chutian Jiang, Hansong Zhou, Xiaonan Zhang, Shayok Chakraborty
ECML PKDD '24: Joint European Conference on Machine Learning and Knowledge Discovery in Databases
Federated learning (FL) enables clients to collaboratively train machine learning models under the coordination of a server in a privacy-preserving manner. One of the main challenges in FL is that the server may not receive local updates from each client in each round due to client resource limitations and intermittent…
Full abstract
Fedar: Addressing client unavailability in federated learning with local update approximation and rectification
Chutian Jiang, Hansong Zhou, Xiaonan Zhang, Shayok Chakraborty
ECML PKDD '24: Joint European Conference on Machine Learning and Knowledge Discovery in Databases
Federated learning (FL) enables clients to collaboratively train machine learning models under the coordination of a server in a privacy-preserving manner. One of the main challenges in FL is that the server may not receive local updates from each client in each round due to client resource limitations and intermittent…
Full abstract
2023
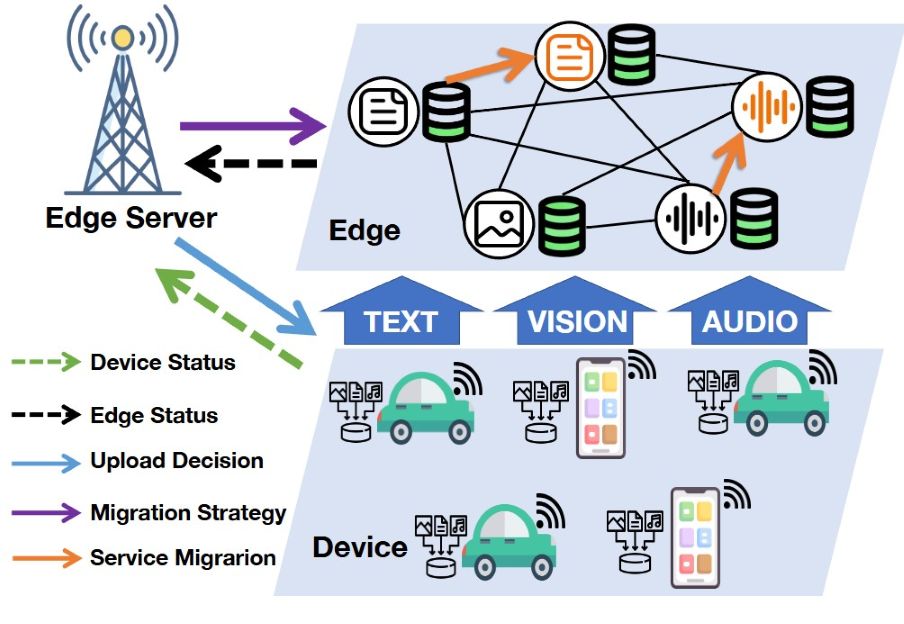
Waste not, want not: service migration-assisted federated intelligence for multi-modality mobile edge computing
Hansong Zhou, Shaoying Wang, Chutian Jiang, Linke Guo, Yukun Yuan, Xiaonan Zhang
MobiHoc '23: Proceedings of the Twenty-fourth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing
Future mobile edge computing (MEC) is envisioned to provide federated intelligence to delay-sensitive learning tasks with multimodal data. Conventional horizontal federated learning (FL) suffers from high resource demand in response to complicated multi-modal models. Multi-modal FL (MFL), on the other hand, offers a more efficient approach for learning from multi-modal…
Full abstract
Waste not, want not: service migration-assisted federated intelligence for multi-modality mobile edge computing
Hansong Zhou, Shaoying Wang, Chutian Jiang, Linke Guo, Yukun Yuan, Xiaonan Zhang
MobiHoc '23: Proceedings of the Twenty-fourth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing
Future mobile edge computing (MEC) is envisioned to provide federated intelligence to delay-sensitive learning tasks with multimodal data. Conventional horizontal federated learning (FL) suffers from high resource demand in response to complicated multi-modal models. Multi-modal FL (MFL), on the other hand, offers a more efficient approach for learning from multi-modal…
Full abstract
2022
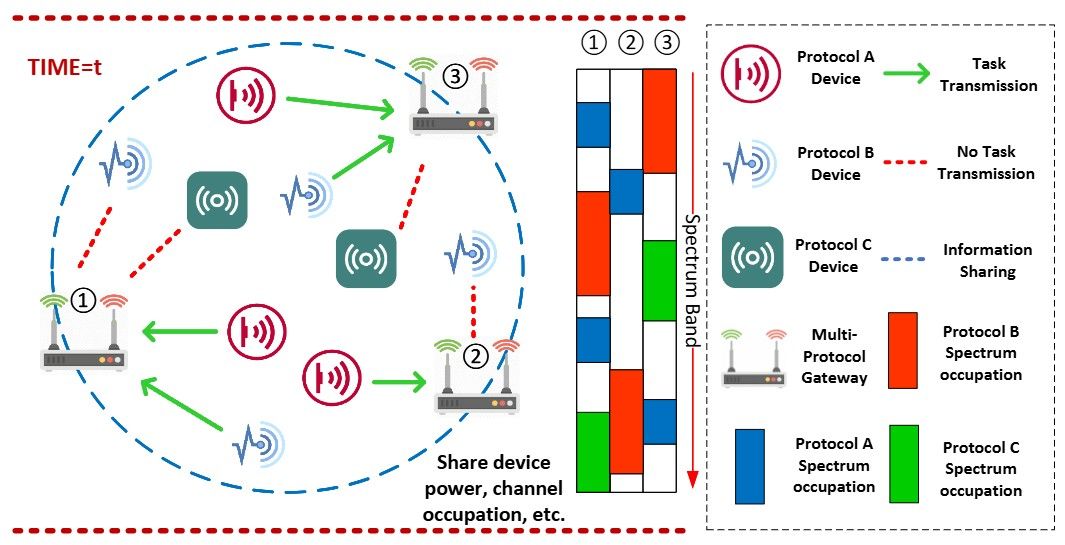
DQN-based QoE Enhancement for Data Collection in Heterogeneous IoT Network
Hansong Zhou, Sihan Yu, Linke Guo, Beatriz Lorenzo, Xiaonan Zhang
MASS '22: IEEE 19th International Conference on Mobile Ad Hoc and Smart Systems
Sensing data collection from the Internet of Things (IoT) devices lays the foundation to support massive IoT applications, such as patient monitoring in smart health and intelligent control in smart manufacturing. Unfortunately, the heterogeneity of IoT devices and dynamic environments result in not only the life-cycle latency but also data…
Full abstract
DQN-based QoE Enhancement for Data Collection in Heterogeneous IoT Network
Hansong Zhou, Sihan Yu, Linke Guo, Beatriz Lorenzo, Xiaonan Zhang
MASS '22: IEEE 19th International Conference on Mobile Ad Hoc and Smart Systems
Sensing data collection from the Internet of Things (IoT) devices lays the foundation to support massive IoT applications, such as patient monitoring in smart health and intelligent control in smart manufacturing. Unfortunately, the heterogeneity of IoT devices and dynamic environments result in not only the life-cycle latency but also data…
Full abstract
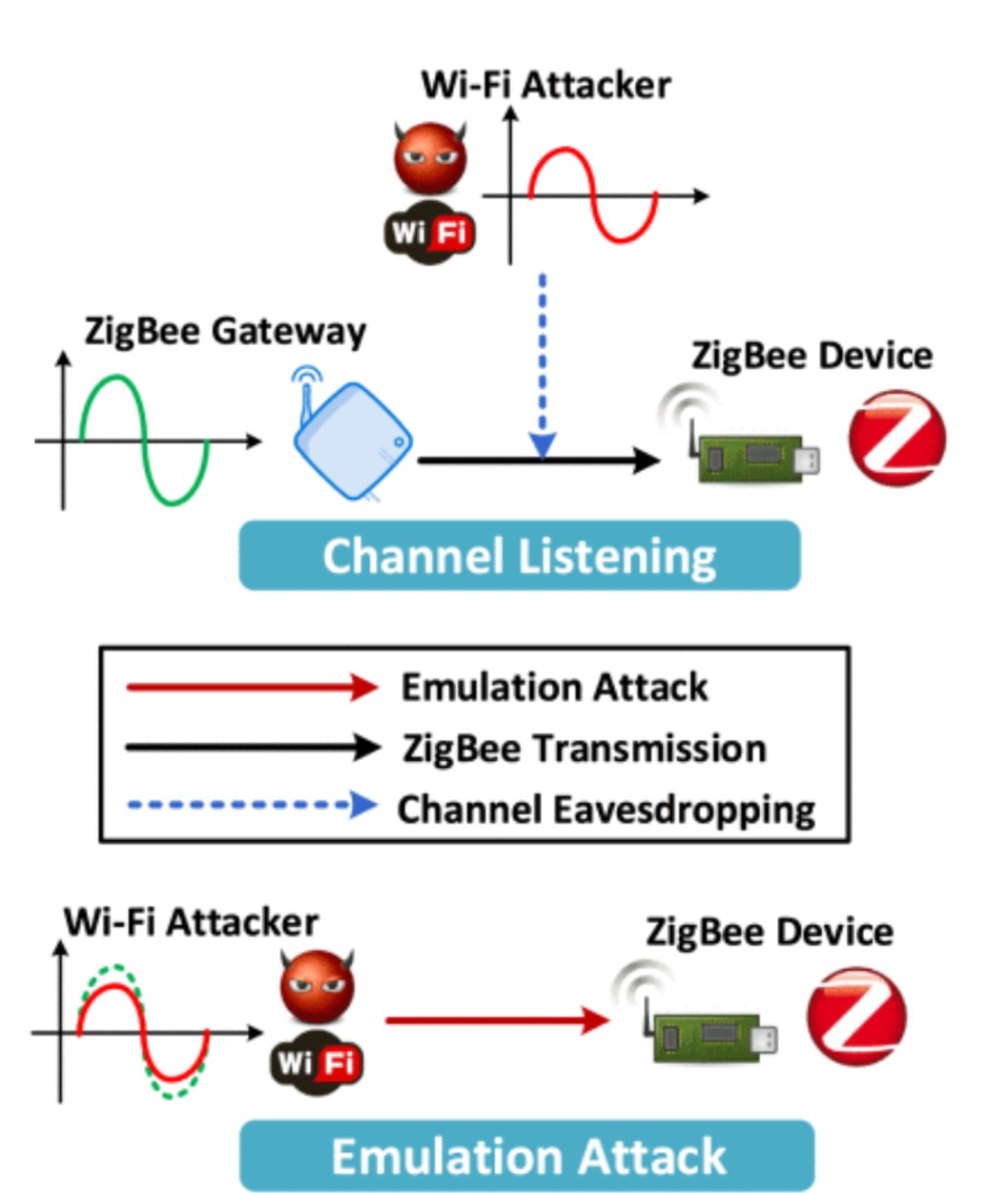
Signal emulation attack and defense for smart home IoT
Xiaonan Zhan, Sihan Yu, Hansong Zhou, Pei Huang, Linke Guo, Ming Li
IEEE Transactions on Dependable and Secure Computing (TDSC) 2022
Internet of Things (IoT) is transforming every corner of our daily life and plays important roles in the smart home. Depending on different requirements on wireless transmission, dedicated wireless protocols have been adopted on various types of IoT devices. Recent advances in Cross-Technology Communication (CTC) enable direct communication across those…
Full abstract
Signal emulation attack and defense for smart home IoT
Xiaonan Zhan, Sihan Yu, Hansong Zhou, Pei Huang, Linke Guo, Ming Li
IEEE Transactions on Dependable and Secure Computing (TDSC) 2022
Internet of Things (IoT) is transforming every corner of our daily life and plays important roles in the smart home. Depending on different requirements on wireless transmission, dedicated wireless protocols have been adopted on various types of IoT devices. Recent advances in Cross-Technology Communication (CTC) enable direct communication across those…