Demo

Real-time Multi-edge Collaborative Inference System
For the vision of cooperative edge intelligence, this demo shows how idle or lightweight devices, such as intelligent assistant in smart home and idle AI edges developed in smart city, can pool their resources to serve modern large language models in real time.
The system runs Meta Llama-3.2-3B-Instruct split across 3 NVIDIA Jetson Orin Nano boards, connected through a TP-Link 5-Port Gigabit unmanaged switch (other network fabrics or protocols could be used with the same design).
Under the hood, I first re-engineered Llama modeling components in HuggingFace Transformers to support the cross-device data pipeline. I then implemented a custom distributed inference engine in PyTorch compatible with the modified components to enable the real-time collaborative inference
- Model: Llama-3.2-3B-Instruct, Full precision
- Device: Jetson Orin Nano
- Connection: TP-Link 5-Port Switch
AI Agent for Rural Health
To improve health outcomes in remote areas with scarce medical resources, we are developing an AI assistant dedicated to supporting behavior change and enhancing patient health. We first built an end-to-end data pipeline that distilled ~2,000 hours of weight-loss consultations into a clean, consistent training JSON data. The process emphasized privacy, conversation quality, and coherent session structure, producing a domain-specific dataset ready for fine-tuning a specialized coaching agent.
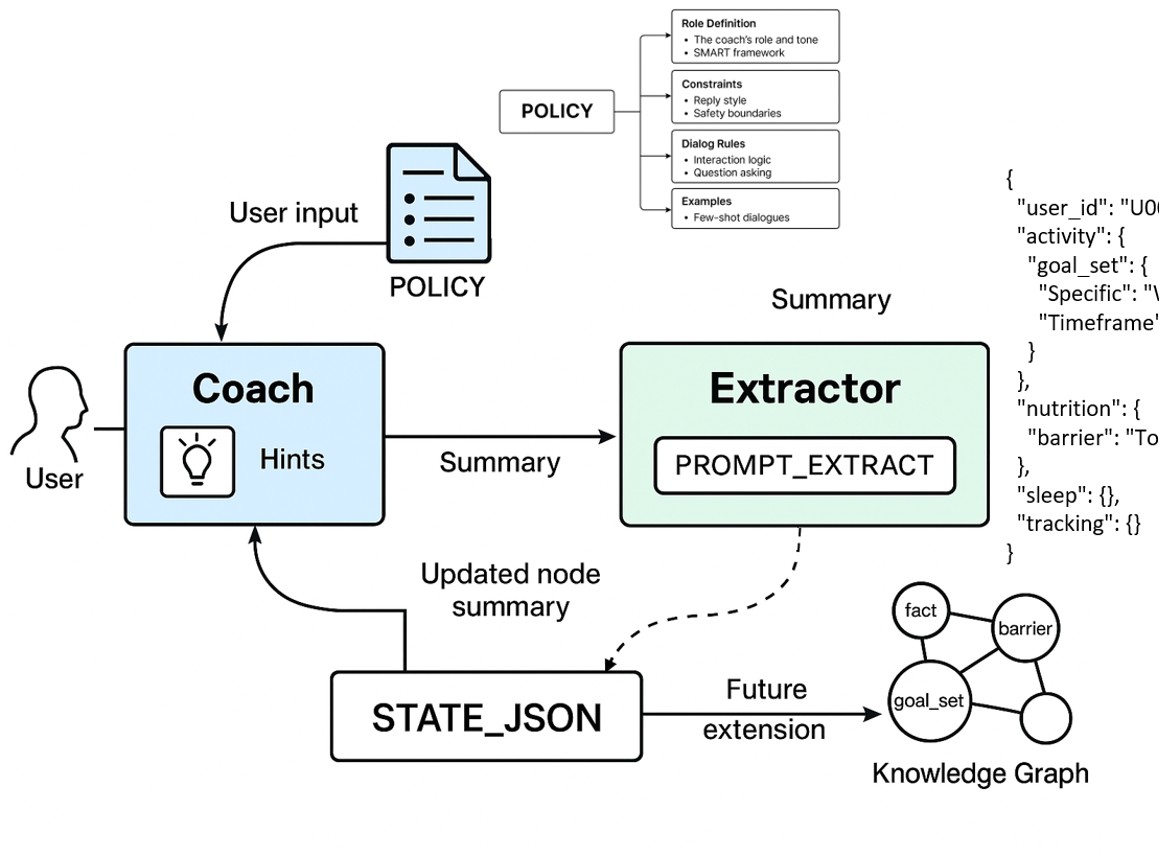
At inference time, we use few-shot prompt engineering and a lightweight knowledge graph to ground responses. Curated exemplars model tone and behavior-change steps, while the graph links goals, habits, and constraints so the agent retrieves relevant guidance and stays consistent across scenarios.
To preserve long-term memory and explainability, we designed a dual-agent loop: a coach that speaks briefly and a structured extractor that writes validated deltas to a shared state for follow-ups across weeks. This architecture stabilizes context, reduces drift, and supports population-level insights later.
- Base model (prototype): Qwen-3-4B
- Fine-tuning dataset: 2000 hrs of weight-losing consultations